
- Глава 1 этого тренинга по SEO, Что такое дублированный контент?
- Обучение SEO Глава 2: В чем проблема дублированного контента?
- Обучение SEO Глава 3: Есть 3 вида дублирующегося контента
- Глава 4 тренинга по SEO: инструменты для решения дублирующегося контента
- Обучение SEO Глава 5: Примеры дублирующегося контента
 Мой персональный тренинг по SEO помогает крупным сайтам решать проблемы с дублированным контентом. SEO Duo Diff Agency рад представить главу своего SEO тренинга по дублированному контенту
Мой персональный тренинг по SEO помогает крупным сайтам решать проблемы с дублированным контентом. SEO Duo Diff Agency рад представить главу своего SEO тренинга по дублированному контенту
Как выбрать SEO тренинг? Начните с поиска в «Тренинге по SEO» и посмотрите на тех, кто находится на обычных результатах поиска Google (а не на платных результатах вверху ...). Все они специалисты, которые понимают и осваивают сегодня SEO ,
Те, кто там, все же не случайно, верно? (Вы видите brandaround theweb, агентство, соучредителем которого я являюсь? Тогда вы видите меня 🙂
Ну что ж, хватит демонстраций, давайте перейдем к той части тренинга по SEO, в которой рассказывается о дублированном контенте, который часто генерируется на больших сайтах с динамическими URL-адресами, ужас в управлении с точки зрения SEO, который требует безупречной строгости.
Глава 1 этого тренинга по SEO, Что такое дублированный контент?
Повторяющееся содержимое возникает, когда 2 или более страниц имеют одинаковое содержимое, как показано на рисунке ниже.

Просто нет? Проблема в том, что веб-мастера считают, что страница - это файл на их сервере, тогда как для Google каждый URL является страницей. А с большими сайтами, содержащими динамические URL, легко увидеть несколько URL, которые ведут к одному и тому же контенту по разным путям.
Обучение SEO Глава 2: В чем проблема дублированного контента?
С точки зрения SEO, дублированный контент был проблемой задолго до Google Panda. Ниже приведен краткий обзор проблем с дублированием контента за последние годы.
Вторичный дополнительный индекс
В первые годы существования Google простая индексация в Интернете была огромной вычислительной задачей. Чтобы решить эту проблему, некоторые URL-адреса, проанализированные как дублирующие или имеющие низкое содержание, были сохранены во вторичном индексе, который называется «дополнительный индекс». Эти URL, с точки зрения SEO, были ссылками второго класса без какой-либо возможности позиционировать себя.
В 2006 году Google включил вторичный индекс в основной без каких-либо видимых изменений в результатах поиска. URL-адреса вторичного индекса были отфильтрованы из результатов поиска по правилам, реализованным в алгоритме.
Бюджет "ползать"
На самом деле нет никаких ограничений для сканирования страниц, тем более что скорость сканирования резко возросла в последние годы, но если робот Googlebot встречает слишком много URL-адресов с идентичным контентом на вашем сайте, он может упасть индексация страниц.
Если существует слишком много разных путей с разными URL, которые ведут к одному и тому же контенту, Google сдастся. В результате страницы с уникальным контентом, который вы хотите индексировать Google, могут вообще не посещаться роботом Googlebot. В лучшем случае они будут ползти реже.
Вы можете почувствовать сканирование своего сайта, перейдя в Инструменты Google для веб-мастеров, выбрав "сканирование" и затем "статистика сканирования".
«Кепка» индексации
Нет ограничения на количество страниц, которые Google будет индексировать на сайте. Кажется, существует динамическое ограничение, связанное с авторитетом сайта. Если вы заполните свой индекс ненужными и дублирующимися страницами, вы можете исключить важные и более глубокие страницы из индекса. Например, если у вас есть тысячи результатов внутреннего поиска, Google может не проиндексировать все страницы вашего продукта (например, граненые меню). Ошибочно полагать, что больше проиндексированных страниц лучше. Часто это наоборот. При прочих равных условиях индексы, полные URL-адресов, ослабляют вашу способность позиционировать себя, особенно с помощью URL-адресов с одинаковым содержанием.
Обновление Панды
Задолго до появления Panda было много дискуссий о возможности наказания за дублирование контента. На самом деле ответ был семантическим. Google не индексирует один и тот же контент дважды, вот и все.
С момента прибытия Panda в феврале 2011 года (август 2011 года во Франции) влияние на дублированный контент стало гораздо более серьезным. До Panda были затронуты только дублированные страницы контента. Начиная с Panda, это весь сайт, на который можно повлиять. Если вы тронуты Panda, даже страницы с одним контентом могут быть затронуты или даже не проиндексированы.
Обучение SEO Глава 3: Есть 3 вида дублирующегося контента
(1) Истинные дубликаты
«Истинный дубликат» - это идентичная страница (по содержанию) на другой странице. Эти страницы отличаются только по URL:

(2) Рядом с дубликатами
«Рядом с дубликатом» отличается от другой страницы (или страниц) только частично. Это может быть блок текста, изображение (то же имя и тэг alt), видимый даже порядок содержимого.

Точное определение идентичного содержания частично трудно определить. Больше в обучении SEO.
(3) междоменные дубликаты
«Междоменный дубликат» происходит, когда 2 сайта используют один и тот же контент.

Эти дубликаты страниц могут быть «истинными» или «близкими». И в отличие от некоторых людей считают, что страницы с дублирующимся контентом между сайтами могут быть проблемой для законного оригинального контента (отсюда интерес ссылки на страницу Google+ на свой сайт, чтобы немедленно делиться любым новым контентом, чтобы приобрести авторство в глазах гугла элементарно нет?).
Глава 4 тренинга по SEO: инструменты для решения дублирующегося контента
(1) 404 (не найден)
Самый простой способ - удалить дублирующийся контент, вернув ошибку 404. Если контент не имеет значения для посетителей и отсутствует или мало входящего трафика и ссылок, удалите его. действительный вариант.
(2) Перенаправление 301
Другой способ удалить дублирующуюся страницу содержимого - это перенаправить 301. Перенаправление 301 указывает поисковым системам, что страница была навсегда перемещена на другой URL. С точки зрения SEO, большая часть преимуществ входящих ссылок со старой страницы - это новости. Это хороший вариант для удаления дублирующегося контента. Использование канонического URL также может иметь значение, но это уже другая тема.
(3) Robots.txt
Другой вариант - оставить дублированный контент видимым для посетителей, но заблокировать его для роботов поисковых систем с файлом robots.txt. Это выглядит так:

Одним из преимуществ использования файла robots.txt является то, что относительно легко заблокировать полные каталоги или даже URL-адреса. Недостатком является то, что это часто является крайним решением, а иногда даже ненадежным. Кроме того, это не удалит уже проиндексированный контент. Он также не рекомендует сканерам поисковых систем сканировать ваш сайт, и они не рекомендуют использовать robots.txt для решения проблемы дублирующегося контента.
(4) Мета Роботы
Вы также можете использовать мета-роботов, также называемых noindex, в исходном коде страниц в части «заголовка», например:

Эта директива говорит роботам не индексировать страницу и не следовать ссылкам, содержащимся на ней. Это лучше с точки зрения SEO, чем robots.txt. Более того, он может генерироваться динамически в коде, который является более гибким.
Другое используемое значение - «NOINDEX, FOLLOW», когда роботы просят не индексировать страницу, а переходить по ссылкам в содержимом страницы. Это может быть полезно для внутренних страниц результатов поиска, например, блокируя определенные варианты URL при переходе по ссылкам на созданные страницы.
Примечание. Абсолютно бесполезно добавлять на страницу роботов мета-тегов «INDEX, FOLLOW», поскольку любая страница индексируется по умолчанию.
(5) Rel = Канонический
В 2009 году поисковые системы согласились создать директиву rel = canonical. Это позволяет веб-мастерам определять каноническую версию для каждой страницы. Этот тег идет в заголовок страницы, вот пример:

Когда поисковые системы попадают на страницу с каноническим тегом, они назначают страницу каноническому URL, который вы определили, без учета URL-адреса, который направил их на эту страницу. Например, если робот достигает указанной выше страницы с URL-адресом www.example.com/index.html, поисковая система не будет индексировать дополнительный неканонический URL-адрес.
Очень важно: будьте осторожны, чтобы не включать идентичный канонический URL в заголовок всего сайта, а назначать канонический URL каждой странице вашего сайта. В противном случае результаты могут быть катастрофическими. Ваш сайт или ваши cms должны быть хорошо закодированы, чтобы избежать этого. Просмотрите исходный код своих страниц, чтобы убедиться, что канонические URL-адреса соответствуют странице, а не домашней странице страницы.
(6) Google URL для удаления
В Google Webmaster Tools вы можете запросить удаление страницы (или каталога) из индекса вручную (см. Изображение ниже)
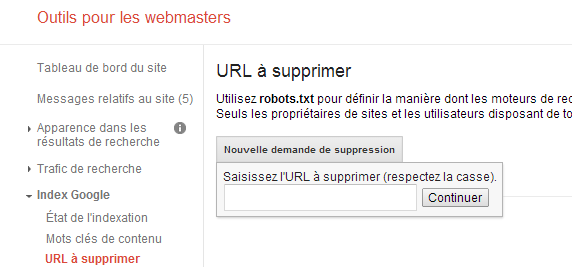
Но, что делает concerneras Google, он также будет сделать для Bing, Yahoo ... Запрос на удаление URL-адрес в Google ОПВ используется в качестве последнего средства, если Google настаивает на сохранении URL в индексе.
(7) Настройки Google URL
Вы также можете использовать «параметры URL», чтобы указать настройки, которые Google должен игнорировать (что блокирует индексацию страниц с этими настройками).
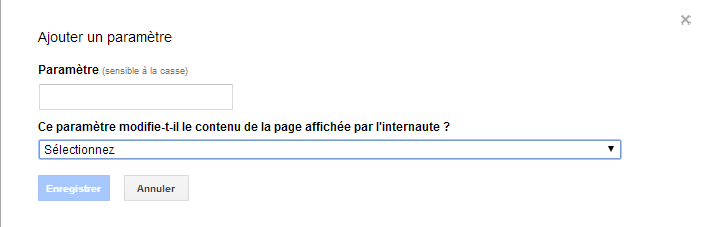
Эти изменения, конечно, влияют только на Google, и Google может принять решение об изменении ваших настроек по своему усмотрению. Используйте только в крайнем случае.
(9) Rel = Prev & Rel = Next
В сентябре 2011 года Google разрешает разбивать страницы результатов поиска на дубликаты контента. По сути, постраничные результаты - это поиски, в которых результаты разбиты на блоки. И у каждого блока есть свой URL.
Теперь вы можете сообщить Google, как содержимое с постраничной связью связано друг с другом, используя теги Rel-Prev и Rel-Next, как в примере ниже:
В этом примере поисковый робот находится на странице 3 результатов поиска, а теги rel = "prev" и rel = "next" указывают на подкачку на страницу 2 и страницу 4.

(10) Внутренняя сетка сайта
Помните, что лучший способ борьбы с дублированным контентом - избегать его создания. Конечно, кроме того, что это не всегда возможно. Тем не менее, если вы начнете сталкиваться с дюжиной повторяющихся проблем, вам, возможно, придется пересмотреть вашу внутреннюю сетку ссылок и структуру вашего сайта.
При решении проблемы с дублированным контентом с помощью перенаправления 301 не забудьте изменить внутренние ссылки вашего сайта, заменив старый URL-адрес новым. Внутренние ссылки являются сильным сигналом, поэтому, если вы отправите URL-адреса в вашей карте сайта со ссылками на старый URL-адрес, вы можете потерять доверие и вызвать проблемы.
(11) Rel = »альтернативный» hreflang = »x»
С февраля 2012 года Google представила новый способ обработки переведенного контента, а также языка с региональными вариациями (например, американский английский или английский английский). Реализация этих тегов сложна и зависит от ситуации, но вот полное руководство на английском языке атрибут hreflang = »x» ,
Лучшее решение с точки зрения SEO - это размещение сайта на региональном домене в .us, .uk и т. Д. Чистые игроки, такие как Amazon, не ошибаются.
Обучение SEO Глава 5: Примеры дублирующегося контента
(1) "www" против Нет-WWW
Относительно всего сайта, это, безусловно, приоритетный преступник. Независимо от того, есть ли у вас плохие пути внутри или вы привлекли ссылки или социальные ссылки на неправильный URL-адрес, у вас есть версия "www" в качестве версии не "www" на проиндексированных URL-адресах вашего сайта.

Решение состоит в том, чтобы определить канонический URL для всего сайта следующим образом:
<link rel = "canonical" href = "http://example.com/" />
Все, что вам нужно сделать, это включить его в исходный код в разделе заголовка вашего сайта.
После этого вы можете сообщить Google в Инструментах для веб-мастеров адрес, выбранный в настройках сайта, или позволить Google определить ваш канонический URL-адрес.
(2) Постановка нового сайта (постановка)
При редизайне веб-сайта типичным сценарием является размещение вашего нового сайта с содержимым старого на поддомене или даже временным доменом, который приводит к дублированию контента на двух URL, например:

В идеале эти проблемы решаются архитектурой сайта. В большинстве случаев безопаснее размещать защищенные страницы в NOINDEX. Кэдди и страницы завершения заказа не имеют никакого отношения к поисковому индексу. Я не рекомендую использовать перенаправления 301 со страниц https в их версии http, вы рискуете их обезопасить.
(5) Дубликат домашней страницы
Это отличная классика дублированного контента. Проблема возникает, когда имя домена отображает домашнюю страницу, которая имеет определенный URL, например, такой:

Хотя эту проблему легко решить с помощью перенаправления 301, лучшим решением будет добавить meta rel = canonical на домашней странице без /index.htm, чтобы сохранить согласованность и избежать проблем с дублированием контента. на весь сайт.
(6) идентификаторы сессий
Некоторые сайты (особенно сайты электронной коммерции) помечают каждого нового посетителя настройкой отслеживания. Иногда этот параметр добавляется в URL и индексируется, создавая что-то вроде этого:

Таким образом, вы можете создать дубликат для каждого идентификатора сеанса и комбинации страниц, которые будут проиндексированы. Идентификаторы сеансов в URL могут создавать тысячи проиндексированных дублированных страниц контента.
Наилучшим вариантом, если это возможно в вашей cms, является удаление идентификатора сеанса из URL и сохранение его в файле cookie. В противном случае потребуется имплантировать rel = canonical на весь сайт. При желании вы также можете заблокировать настройку идентификатора сеанса в Google Webmaster Tools и Bing Webmaster Central.
(7) Отслеживание партнеров.
Эта проблема очень похожа на случай № 6, когда сайты добавляют переменную отслеживания своим партнерам. Эти переменные часто направляются на целевую страницу, например:

Это менее серьезно, чем в случае 5, но может создать реальную проблему дублированного контента. Решения идентичны случаю URL с идентификаторами сеансов. Лучшее решение - записать идентификатор партнера в файл cookie и создать перенаправление 301 на канонический URL-адрес страницы. В противном случае вы также можете заблокировать настройку партнерской ссылки, если это возможно, в вашей cms.
(8) Пути дубликата контента
Создание дублирующих путей к странице не создает особых проблем, если только ваши дублирующие пути не генерируют дублирующиеся URL-адреса. Например, предположим, что страница продукта может быть доступна следующими тремя способами:

В этом случае на страницу продукта Ipad2 можно попасть двумя категориями и автоматически сгенерированным тегом пользователя. Автоматически сгенерированные пользовательские теги могут вызвать огромные проблемы с внутренним дублированием контента, поскольку они создают неограниченные версии каждой страницы.
В идеале эти пути к URL не должны создаваться вообще. Каждая достигнутая страница должна иметь только один возможный URL с точки зрения SEO.
Если у вас уже есть варианты индексированного URL-адреса, необходимо установить редирект 301 или канонический URL-адрес. Убедитесь, что вы регулярно проверяете в Инструментах для веб-мастеров, что нет повторяющихся URL-адресов и ошибок 404. Если это так, вам следует проверить архитектуру вашего сайта.
(9) Функциональные параметры
Функциональные параметры - это параметры URL, которые слегка изменяют страницу, но не имеют значения SEO и, по сути, создают дублированные страницы контента. Например, предположим, что все страницы вашего продукта имеют версию для печати, а версия для печати имеет определенный URL, например:

В этом случае URL «print = 1» указывает на версию для печати, которая обычно имеет такое же содержимое, но имеет измененный шаблон. Лучше всего не индексировать URL-адреса при помощи перенаправления 301 и лучше канонического URL-адреса.
(10) Международные дубликаты
Это классический случай, когда компании хотят нацеливаться на несколько стран с одного и того же доменного имени, часто в .com для простоты. Как в примере ниже
К сожалению, эту проблему сложно решить. Google в большинстве случаев индексирует правильный контент в нужных странах, а в других даже при геолокации это не произойдет. Часто лучше ориентироваться на язык, а не на страну из одного домена, но часто бывают особые случаи, когда лучше отделить контент для конкретной страны, например, тарифы. Лучшее решение - разместить сайт по географическому IP-адресу, расположенному в каждой стране, и на языке оригинала.
(11) Поиск вариантов
Результаты поиска на сайте часто дают близкие дубликаты, предлагая варианты страницы, основанные на поиске, часто путем изменения содержания страницы следующим образом:

Решение, а не индексировать варианты, зная, что оно может принести больше вреда, чем пользы.
(13) поисковая нумерация страниц
Разбивка на страницы - это простая для понимания проблема, но ее трудно решить. Всякий раз, когда вы разделяете внутренний поиск на отдельные страницы, вы получаете постраничный контент. URL-адреса легко визуализировать:

По сотням результатов поиск может легко генерировать десятки результатов. Хотя результаты отличаются, многие важные элементы страницы идентичны (заголовок, метаописание, заголовок, контент, шаблон и т. Д.). Добавьте к этому, что Google не является большим поклонником «поиска в поиске» (встраивая свои страницы результатов в ваши).
Google пытается без особого успеха решить проблему нумерации страниц. Недавно Google представил Rel = Prev и Rel = Next. Первоначально он должен работать, но данных для его доказательства не так много, его сложно и сложно реализовать, и поисковые системы, такие как Bing, не принимают его во внимание.
Есть 3 других жизнеспособных решения, которые сильно зависят от ситуации:
- Вы можете добавить Meta Noindex, следите за результатами поиска на страницах 2+. Вы позволяете Google сканировать контент, разбитый на страницы, без их индексации.
- Вы можете создать страницу «Просмотреть все», которая связана со всеми результатами поиска по URL. И пусть Google обнаружит это. Это еще одна любимая опция Google.
- Вы можете создать страницу «Просмотреть все» и включить канонический URL на эту страницу. Это официально не признано практичным, но страницы больше не являются дубликатами в традиционном смысле. Возможно, этот метод является нарушением использования rel = canonical.
Вот ресурс, который идет дальше в этой области: обсуждение поисковой нумерации страниц
Разбиение на страницы часто трудно решить и создает бесконечные проблемы.
Моя рекомендация: перенаправлять результаты поиска на поддомен, чтобы избежать дублирования контента в основном домене. Пример: www.recherche.domaineprincipal.com
(14) Вариации продукта
Страницы вариантов продукта - это страницы, которые мало различаются (цвет, размер, вес ...), такие как:

Может быть трудно поддаться искушению проиндексировать каждый вариант, надеясь, что все они появятся в результатах поиска, но в большинстве случаев это бесполезно. Но вы можете либо:
- Do Rel = Next и Rel = Prev
- Включите канонический URL для каждого варианта, который перенаправляет на главную страницу продукта.
Независимо от того, являются ли ваши URL-адреса статическими или динамическими, создаваемые варианты будут создавать одинаковые проблемы с дублированным контентом.
(15) Гео-локализованные вариации
Было время, когда было достаточно изменить название города в элементах страницы, создавая страницу за городом, чтобы позиционировать себя в поисковой выдаче. Это создает URL-адреса, подобные этим:

С 2011 года локальный SEO стал не только намного более сложным, но все эти страницы являются "Near Duplicates". Теперь, если вы хотите позиционировать себя, ориентируясь на определенные города, вы должны создавать страницы по городам с уникальным контентом. Если у вас есть бизнес с агентствами или магазинами в нескольких городах, то создание определенной страницы, связанной со страницей Google Адресов, будет выигрышной ставкой.
(16) Синдицированный контент
Синдицированный контент - это контент другого сайта, опубликованный на вашем сайте с разрешения владельца другого сайта. Так что вопиющий случай дублирования контента с другого сайта, который наверняка поднимет красный флаг от Google Panda, повлечет за собой ручное наказание.
Хотя эта практика является законной, вам следует создать ссылку на исходный контент с каноническим URL-адресом, обозначающим исходный контент, чтобы гарантировать, что Google Panda не оштрафован за дублированный контент.
(17) переадресованный контент
То же самое, что и контент, созданный в профсоюзе, за исключением того, что вы не спрашиваете разрешения других. БОЛЬШОЙ КРАСНЫЙ ФЛАГ в глазах Гугла и закона.
Если вам действительно небезразличен контент других людей, то перепишите его, изложив свои собственные точки зрения или опыт.
Обучение SEO Глава 6: Что такое канонический URL?
Используете ли вы редирект 301 или канонический URL, будьте осторожны, чтобы не сделать следующую ошибку:

Проблема в том, что product.php - это шаблон. Вы просто канонизировали все свои продукты по одному URL-адресу, который, вероятно, даже не является страницей продукта, является катастрофой. Вероятно, он также включает в себя такой параметр: "id = 1234"
Каноническая страница - это не всегда самый простой URL-адрес страницы, это самая простая версия URL-адреса, которая генерирует уникальный контент. Допустим, у вас есть 3 URL, которые генерируют одну и ту же страницу продукта:

2 из этих версий по сути дубликаты страниц. Версия для печати и сессии. Однако параметр id необходим для определения того, какой это продукт.
Вывод:
Плохая канонизация может привести к катастрофическим последствиям в некоторых случаях. Тщательно спланируйте и убедитесь, что вы выбрали правильные страницы, чтобы их можно было объединить до их объединения.
SEO Обучение Глава 7: Инструменты для диагностики дублированного содержания
Теперь, когда вы знаете, как выглядит дублированный контент, вот несколько полезных инструментов для диагностики дублированного контента на вашем сайте:
(1) Инструменты Google для веб-мастеров
В Инструментах Google для веб-мастеров вы можете проверить, есть ли у вас дубликат списка заголовков и мета-описаний, который Google сканировал и идентифицировал. Даже если это не позволяет вам проверять все проблемы с дублированным контентом на вашем сайте, это хорошая отправная точка, зная, что многие дублированные URL-адреса контента будут иметь одинаковые теги Title и Meta Description.
В вашем аккаунте Инструментов Google для веб-мастеров перейдите к «появлению в результатах поиска», а затем к «html extensions», и вы увидите следующую таблицу:
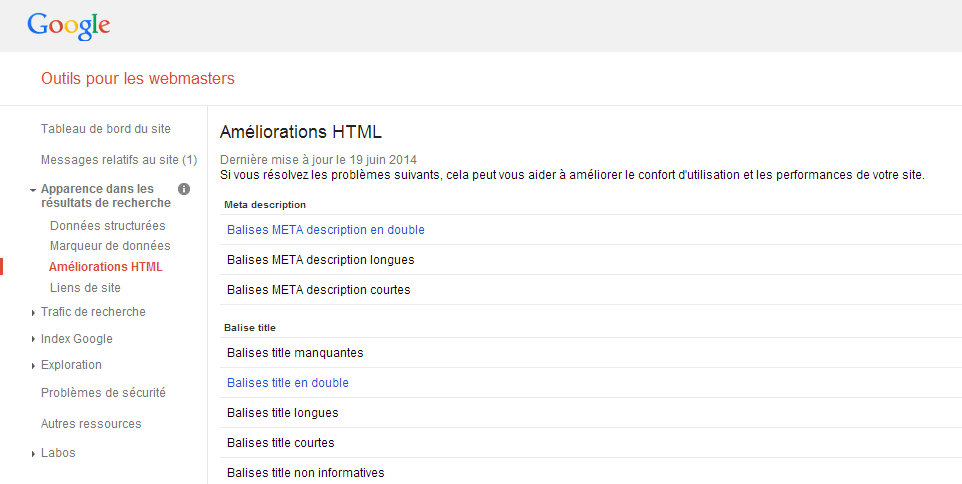
Вы можете нажать «Дублировать мета-теги описания» и «Дублировать теги заголовка», чтобы увидеть список дублированных страниц. Это хороший способ начать.
(2) Заказ сайта Google:
Если у вас уже есть представление о том, откуда могут возникнуть проблемы с дублированным контентом, команда Google «site:» - это мощный и гибкий инструмент, поскольку вы можете использовать его в сочетании с другими операциями поиска.
Скажем, например, что вы думаете, что у вас есть проблема с дублирующимся контентом на главной странице вашего сайта. Вы можете использовать команду «site:» с оператором «intitle» следующим образом:

Всегда помещайте заголовок в кавычки, чтобы захватить полное предложение, и всегда используйте свой корневой домен без «www», чтобы обеспечить максимально возможное сканирование при поиске дублированного контента. Это обнаружит версии "www" и не www.
Другая очень полезная и мощная комбинация - это использование «site:» плюс оператор «inurl:». Вы можете использовать эту команду для обнаружения параметров, вызывающих дублирование контента, таких как различные версии поиска, описанные выше.

Оператор "inurl" также может обнаружить используемый протокол. Это обнаружит, были ли проиндексированы копии защищенных страниц следующим образом:

Вы также можете смешать оператор «site:» с часто используемым текстом, чтобы найти «почти дубликаты» (например, блоки повторяющегося контента). Для поиска возможного блока контента просто добавьте этот контент в кавычки:

Конечно, вы можете искать, помещая заголовок или текст в кавычки без команды «site:», чтобы увидеть, дублировали ли другие сайты ваш контент.
Эти несколько примеров должны помочь вам выявить проблемы с дублированием контента, позволяя вам увидеть то, что видит Google.
(3) Кричащая лягушка
Screaming Frog - это один из наиболее часто используемых в мире инструментов SEO для аудита сайта. Это также позволяет находить множество проблем с дублированным контентом (URL, заголовки, метаописания, альтернативные изображения ...).
(4) Ваш собственный мозг
Поскольку выявление дублированного контента - настоящая детективная работа, вы должны использовать свой собственный мозг. Доверия к инструментам часто недостаточно, и вы знаете свой сайт лучше, чем инструменты, которые его сканируют. Инструмент не сможет выявить проблемы с дублированным содержимым, например, с разными путями, ведущими к странице с динамическими URL-адресами, так как эти пути запускаются щелчком в разных местах посетителем или заполнением полей, как в навигации граненые или внутренние исследования; И инструмент не нажимает на ваш сайт и заполняет еще меньше полей. Это ссылки для сканирования вашего сайта. Поэтому вы должны просмотреть свой сайт, чтобы определить, где могут возникнуть проблемы с дублированным содержимым.
Затем речь пойдет об использовании правильных опций для решения проблем с дублированным контентом, чтобы сделать ваш сайт еще более «дружественным к SEO».
Таким образом, вы можете понять огромную пользу от индивидуальное обучение SEO который позволит вам уйти с SEO-стратегией, адаптированной к вашему сайту или узнать выбрать SEO агентство достойный имени.
Давай поговорим вместе
Глава 1 этого тренинга по SEO, Что такое дублированный контент?Обучение SEO Глава 2: В чем проблема дублированного контента?
Вы видите brandaround theweb, агентство, соучредителем которого я являюсь?
Глава 1 этого тренинга по SEO, Что такое дублированный контент?
Просто нет?
Обучение SEO Глава 2: В чем проблема дублированного контента?
Отсюда интерес ссылки на страницу Google+ на свой сайт, чтобы немедленно делиться любым новым контентом, чтобы приобрести авторство в глазах гугла элементарно нет?