

SEO развивается изо дня в день, и машинное обучение занимает большое место, давая начало все более и более продвинутым семантическим инструментам, а также все более и более интеллектуальным поисковым системам. Этот пост - мой рождественский подарок, где я учу вас, как создать собственную внутреннюю семантическую сетку вокруг темы «Звездных войн».
Как и в саге, я разрезал этот билет на 3 части, которые я буду транслировать с 9 по 25 декабря 2015 года.

Прежде чем начать, вот список, инструменты, которые могут улучшить его семантический корпус. Благодаря пересечению большого количества инструментов уровень шума ограничен и мы достигаем очень хороших результатов.
Инструменты
Конечно, есть инструменты Google:
Тогда есть инструменты, посвященные семантическому анализу.
- Лейпцигский университет предоставляет базу данных под названием «Французский корпус», состоящую из почти 37 миллионов предложений, или около 700 миллионов слов.
http://wortschatz.uni-leipzig.de/ws_fra/
- Visiblis - это набор семантического программного обеспечения, которое позволяет лучше писать его содержимое и заголовки, оптимизируя при этом его сетку и ранг семантической страницы. Я считаю, что это лучший семантический инструмент SEO на данный момент для тех, кто новичок или у которого нет слишком сложных потребностей (сайт с более чем 100 000 URL для анализа, слишком длинное содержание, специальная кодировка, страницы на английском языке). , сайты в javascript ...).
Поздравляем Джерома Россигнала, который дает SEO-сообществу очень практичный инструмент по доступной цене.
http://www.visiblis.com
Наконец, я не буду перечислять большое количество API-интерфейсов, предназначенных для интеллектуального анализа данных, потому что, по моим сведениям, их минимум 12.
В своей статье я собираюсь использовать API-интерфейс Aylian, который дает 1000 запросов в день, чтобы показать вам его потенциал и создать собственную внутреннюю семантическую сетку. API Aylien остается по разумной цене (199 долларов в месяц) за 180 000 анализов.
- Aylien - это API, который позволяет анализировать текст, извлекать информацию и извлекать данные (микроформаты, теги) с использованием машинного обучения для извлечения смысла и эффективности из текстового и визуального контента.
http://aylien.com/
Эпизод 1: Выбор страниц поддержки
Требуется много страниц поддержки, чтобы повысить целевую страницу.
Избегайте классических ошибок при выборе страниц поддержки и слушайте советы Мастера Йоды:
- Страницу с окончанием публикации вы избежите
- Страница, не исследованная Google, откажется
- Страница с глубиной слишком сильна, вы устраните
- Страницу без отчета вы исключите
У SCiFI-Universe есть умный срез: рабочая карта, которая затем разрезается на циклы (оригинальная трилогия, прелогия, новое трило), а затем на медиа-карты (фильмы, книги, игры) и издания (DVD, редактирование). особенная игра, роман в карманном варианте ...)
Я дам вам несколько инструментов для извлечения страниц поддержки:
Query Explorer
Этот инструмент позволяет извлечь все данные из вашего аккаунта Google Analytics
Это простой в использовании, выполните следующие действия, чтобы извлечь URL, которые генерируют трафик SEO
1 / Настройте свой аккаунт GA 
2 / Укажите следующие параметры:

3 / Нажмите «Выполнить запрос», и вы получите свой первый список.
Пакет Р
С R это еще проще, потому что я создал специальную функцию.
Вам просто нужно указать в параметре дату начала, дату окончания и идентификатор, который соответствует параметру p URL в Google Analytics.
Таким образом, вы получаете готовый к использованию фрейм данных.
analyticsGetOrganicLandingPage <- function (id, startdate, enddate) {DF <- google_analytics (id = id, start = startdate, end = enddate, metrics = "ga: сеансы", размеры = "ga: landingPagePath", sort = "-ga : сеансы ", фильтры =" ga: medium = @ органический, ga: source = @ google ", samplingLevel =" WALK ") DF <- summaryBy (сессий ~ landingPagePath, data = DF, FUN = сумма) имен столбцов (DF) < - c ('Address', 'Sessions') DF <- организовать (DF, -Sessions) возврат (DF)}
Ползет с ксену
Начните сканирование своего сайта для получения ценной информации:
- URL (который будет служить идентификатором)
- глубина страницы (уровень)
- повторный код (Status.Code)
- количество входящих ссылок (Links.In)
- количество исходящих ссылок (Links.Out)
Не забудьте ограничить глубину сканирования вашего сканера:
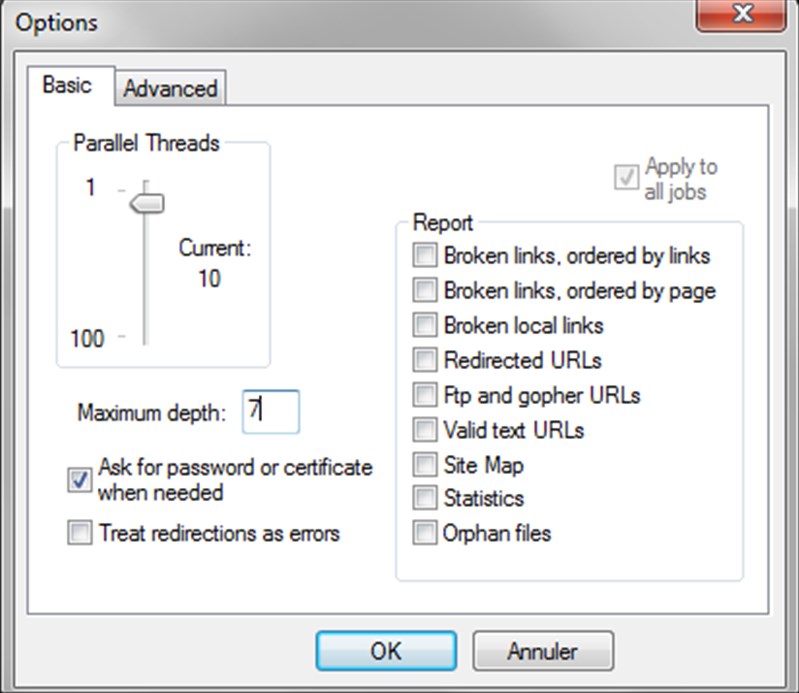
Xenu остается очень простым в использовании, вам просто нужно указать начальный URL.
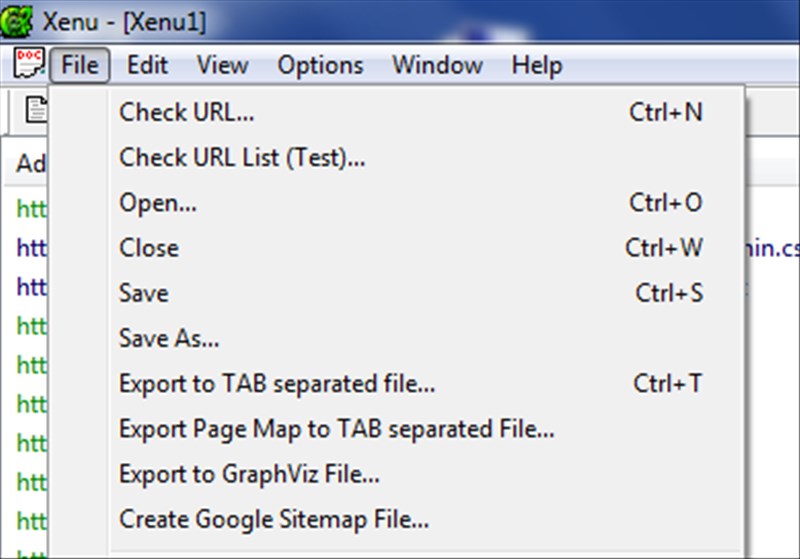
После полного сканирования сайта вы можете экспортировать текстовый файл, содержащий все ссылки.
Экспорт в TAB-файл ...
С помощью R я объединяю результаты списка просканированных страниц со списком страниц с SEO-трафиком и применяю рекомендации Мастера Йоды.
site <- "http://www.scifi-universe.com" # эта переменная после параметра URL-адреса Google Analytics idAnalytics <- "144342" # займет не менее двух последних месяцев DF_analytic <- analyticsGetOrganicLandingPage (idAnalytics , "2015-09-01", "2015-11-30") # укажите путь к текстовому файлу Xenu DF_crawler <- read.csv ("./ projects / scifi-universe.com / xenu_links.txt", header = TRUE, sep = "t") # мы сохраняем некоторые данные DF_crawler <- фильтр (DF_crawler, grepl ("html", Type))%>% select (Level, Links.Out, Links.In, Address, Status .Code, Size #, Title) # мы заменяем URL-адрес сайта пустой строкой, поскольку Google Analytics не указывает имя домена DF_crawler <- as.data.frame (sapply (DF_crawler, gsub, pattern = site, replace = ") ")) # мы объединяем две таблицы DF_merged <- merge (x = DF_analytic, y = DF_crawler, by =" Address ", all.x = TRUE)%>% # мы удаляем URL, где уровень глубины не имеет не найден фильтр (! is.na (Level))%>% # удалить профессионала фильтр основателей больше или равен 8 (as.integer (Level) <8)%>% # сортировка по порядку сеанса (-Sessions) write.table (DF_crawler, file = "./projects/scifi-universe.com/page -support.csv ", sep ="; ", col.names = FALSE)
Ползать с Кричащей Лягушкой
Screaming Frog более полная, чем Xenu, и позволяет получать больше информации с лицензией 99 фунтов в год:
- URL (который будет служить идентификатором)
- глубина страницы (уровень)
- повторный код (Status.Code)
- Мета Роботы (Meta.Robots.1)
- тег H1 (H1.1)
- канонический (Canonical.Link.Element.1)
- количество входящих ссылок (Inlinks)
- количество исходящих ссылок
Это может сэкономить вам много времени, если вы не владеете R, поскольку оно может пересекать ваши данные во время сканирования с информацией из Google Analytics.
Я написал статью на эту тему: http://data-seo.com/2015/07/09/tutoriel-screamingfrog-v4-decouvrez/
заключение
Это конец эпизода 1, и обычно у вас должен быть список страниц поддержки, готовый к использованию.
Внутреннюю семантическую сетку можно настроить, работая с такими инструментами, как R, Xenu, Google Analytics.
Я работал с R на моем любимом языке, но использую технологию, которая вам наиболее удобна.
Я использовал сканер для идентификации страниц поддержки, но в конечном итоге я проделал ту же работу с анализатором журналов.
Этот тип сетки не только поможет вашим пользователям находить статьи, связанные с их исследованиями, но также поможет ботам находить качественные страницы.
В следующем эпизоде вы узнаете, как выбирать целевые страницы и оптимизировать их с помощью Visiblis.

Да пребудет с тобой сила! Продолжение следующего эпизода
Фото предоставлены: StarWars